Organic Agent Memory
Synaptic is a memory backend for AI agents — an organic memory manager that consolidates, prunes, and recombines memories on a nightly dream cycle. This project started out as a fun way to visualize my agents' memories, but it grew into the full memory system. Inspired by how humans store and retrieve memories, built on a foundation of peer-reviewed neuroscience research.

Oh, you're here early!
I'm still working on the public beta of this program, but here's a preview of what it can do. Most of what's shown is shipped; some refinements are still in flight.
Why an organic memory manager
Synaptic is a memory manager for AI agents. While your agent is working, it captures memories — embed, tag, index. Once a night (or on demand), it runs a consolidation pipeline inspired by how biological memory works. The pipeline does four things: it lets the gist of a memory drift toward the larger pattern while keeping the raw source text untouched; it forgets weak material on a weighted curve that protects fragile-but-important traces (the things that ought to matter); it builds connections across distant regions of the bank that no targeted query would have surfaced; and when the context changes — when you swap the Tier 2 model, when new memories shift the meaning of older ones — it re-encodes the affected memories instead of leaving them stale.
That loop runs between retrievals. Recall still works the way you'd expect — your agent asks, Synaptic returns matches. What changes is what's in the bank by the time the agent asks: a graph that's been pruned, recombined, and re-encoded against the current state of the world rather than a static log of everything the agent has ever seen.
I came to this from the wrong direction. I started the project because I wanted to see what my agents looked like when they were thinking — the gears spinning, the patterns connecting, the forest behind the trees. I built the brain visualizer, and it helped, but staring at the bundle of neurons and synapses I'd stitched together I realized I was one step away from a real memory system. I was already storing and indexing memories; I was burning agent tokens to do tagging that didn't need them; the indexing step I was relying on could run locally for free. A week of building later, I had a memory manager that grows with its user, develops connections between memories, and archives the inactive ones — and a name for the thing it does while the host machine is idle. Dreaming.
The brain visualizer is still there, and it's still the prettiest part — but it's the readout, not the product. Underneath it: a consolidation pipeline running on local LLMs you control (Ollama, OpenAI, Anthropic, AirLLM, anything OpenAI-compatible), inside a process bound to 127.0.0.1 by default, with a sensitive-flag that — once flipped on — never sends a flagged memory to Tier 3 or any external endpoint for the rest of its life. The brain shows you what the system is doing. The Dream cycle is what it's for.
What's wrong with traditional memories?
- LLM Memories are just more text to be processed in the current context, bloating more and more over time.
- Recall quality degrades over time as the embedding space saturates.
- The system never thinks about its own contents — it just retrieves them.
- Surprising connections between distant memories never surface unless you ask the exact right query.
- There's no concept of understanding a topic — just facts arrayed against each other.
- If tags aren't strictly curated, they can fragment or mislabel, causing recall to fail.
- The Memory System doesn't teach what's important: The How and The Why, only fact strung together.
What Synaptic does differently
- Triage — every memory gets a salience score; weak ones decay, strong ones reinforce.
- Consolidation — duplicate memories merge; clusters synthesize into single richer entries.
- Cross-region bridges — surprising connections between distant memories surface automatically.
- Schemas — the system abstracts patterns from groups of related memories, developing complex pathways
- Replay — REM-style recombination produces new associations the traditional tagging can't explicitly develop on it's own.
- Context memory — composite frameworks distilled from many specific experiences develop habits and patterns
- Archival — Old Memories lose salience, Synaptic archives them, preventing halluciantions of outdated info.
Do Agents Dream of Electric Sheep?
Once a night (or on demand), Synaptic runs a 12-phase consolidation pipeline modelled on biological sleep stages (Phase 8.7 is dark-launched behind a feature flag in v2.3.0b1 — see the tile below). Each phase corresponds to a real brain mechanism. You can see every phase fire in the Dream Journal panel; you can tune any of them; you can read about why it exists in the citation linked from the panel.
light_encoded. Sub-second per memory.enriched_text.The Atlas
The dashboard's Atlas Connectome Explorer is where you actually look at your AI's mind. Eight tabs, each with focused sub-pages. Here's what you'll see when you walk through it.
CT Scan — live activity
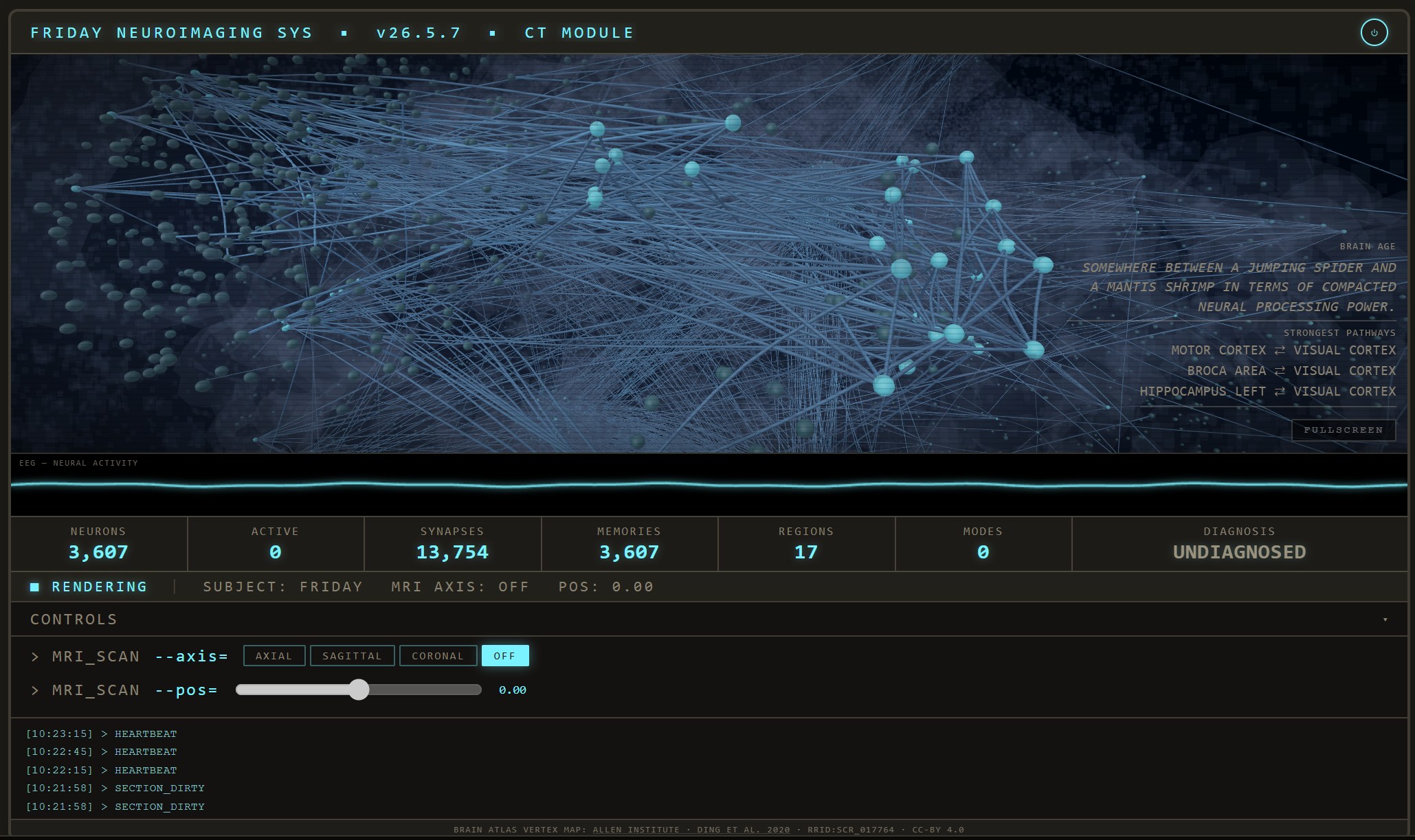
A CT Scan of your Agents' memory bank. Each bright spot is an active Memory, and every strand a Synapse.
Dream Journal — last night's work
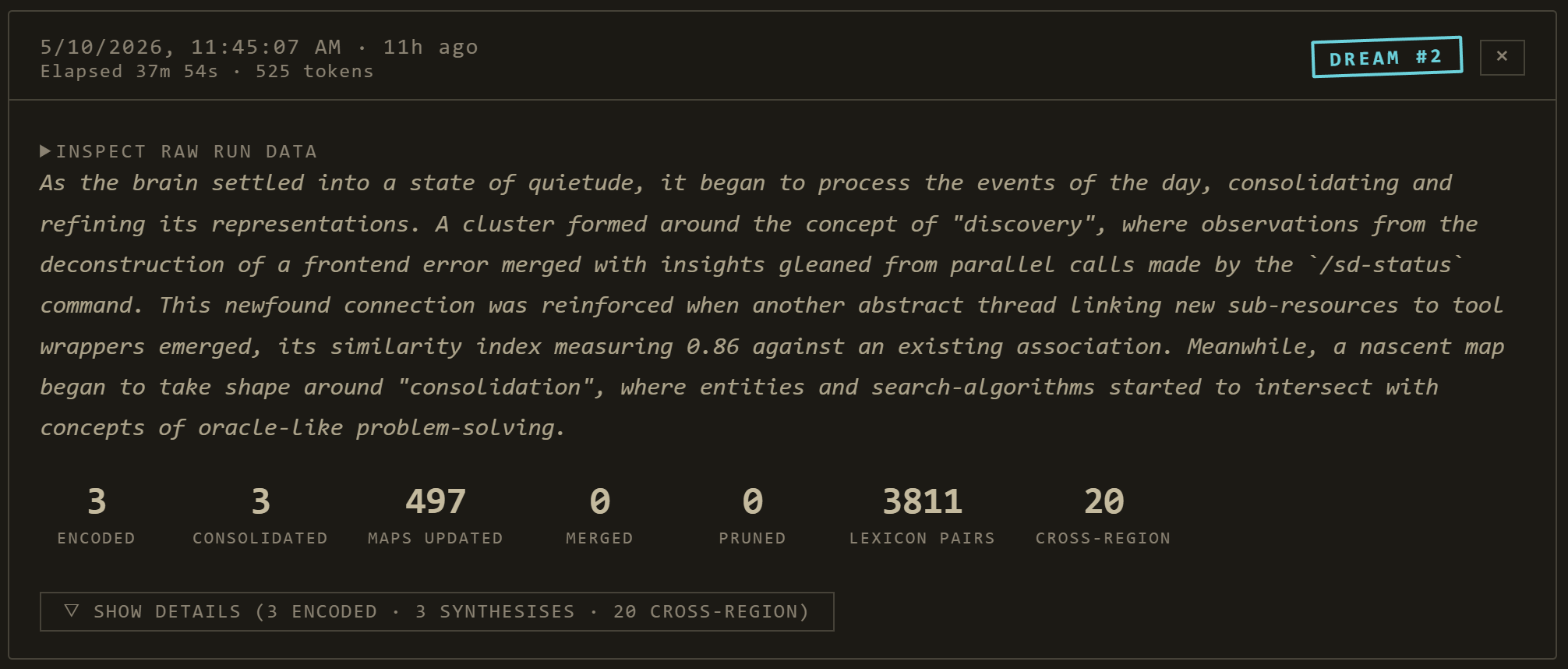
Dream Journal: progress card + generated dream entry per nightly run, with archetype caption + expandable phase details.
Maps — concepts, projects, people, technologies
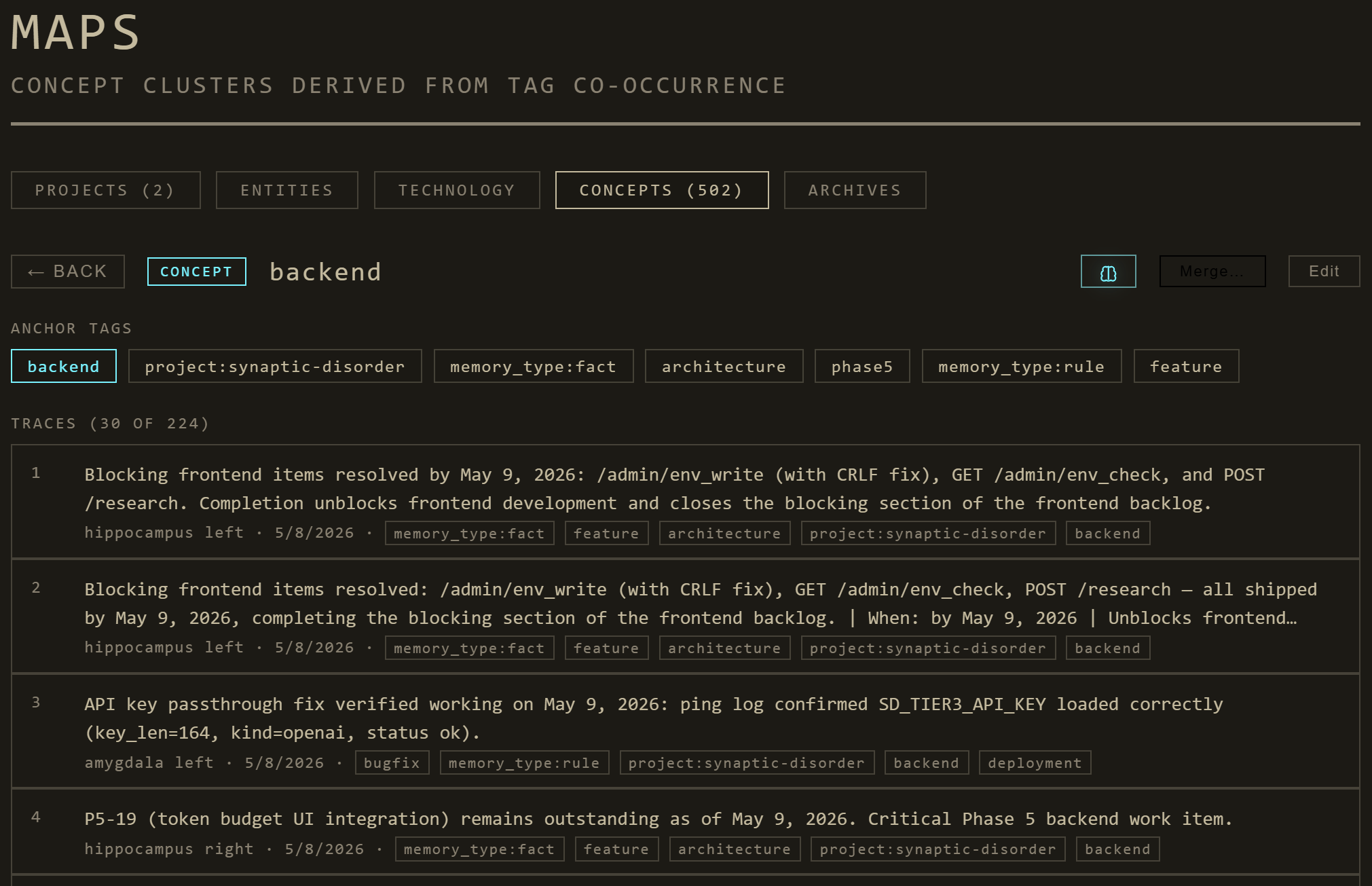
Maps. Connected Topics in your Agents' memory bank.
Trace detail — a single memory's lifecycle
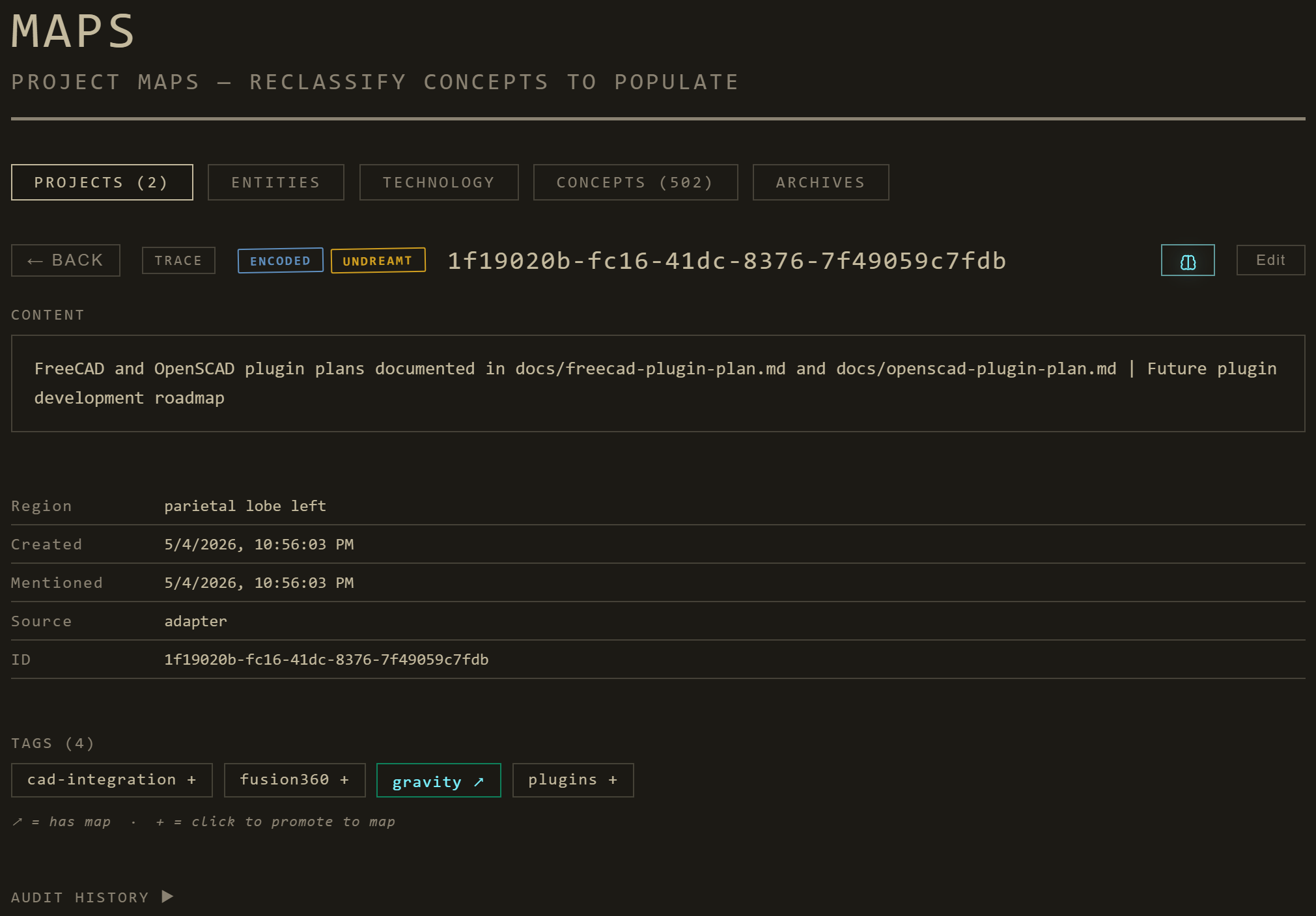
Trace detail: lifecycle badges, salience, recall strength, synthesis lineage, surprising cross-region partners.
What it can do
For the AI agent
- Auto-classified memories — every saved memory lands in the right brain region without manual tagging
- Recall that improves over time — recently used memories get reinforced, irrelevant ones decay
- Surprising associations — the cross-region bridges surface connections you didn't know to ask about
- Schemas — abstract patterns the agent can use to reason about families of memories
- Tier 3 research augmentation — when a topic is thinly populated, the system can fill it via OpenAI / Anthropic / local AirLLM
- Sensitive-aware — flagged memories never reach Tier 3 or external egress; redacted in audit; sticky-on policy
For you
- A morning dream entry — short surreal prose summarizing what consolidated overnight
- Live brain visualization — see your AI's "mind" pulse as it works in real time
- Map view — what concepts/projects/people/technologies are in the bank
- Atlas search — "/" anywhere; prefix-scoped, ranked, recent-history-aware
- Audit log — every consolidation operation, with before/after diffs
- Privacy panel — what's flagged sensitive and why
- Per-tier model controls — local Ollama, OpenAI, Anthropic, AirLLM
- Mobile + remote — Cloudflare Tunnel + bearer-token auth; works from any network
Your bank, your machine, your models
SD Core binds to 127.0.0.1 by default. Your memories never leave the machine they were saved on unless you turn that off, and turning it off is deliberate — Cloudflare Tunnel or Tailscale plus a bearer-token gate on every request, no exceptions. Nothing phones home; there is no telemetry, no analytics, no opt-in usage stats. Once you've installed it, the dashboard never reaches out.
Every tier of the consolidation pipeline runs on a model you choose. Tier 1 (the always-on encoder), Tier 2 (the nightly worker), Tier 3 (the Oracle / research call) are independently configurable: Ollama on the same box, AirLLM streaming a 70B model off your SSD, OpenAI, Anthropic, or any OpenAI-compatible endpoint you point at. No vendor lock, no required cloud account. If you want the whole pipeline running on a Raspberry Pi with llama3.2:1b, you can; if you want Tier 3 to be Claude Opus, you can.
The sensitive-flag is sticky-on by design. Once a memory is flagged sensitive — by you, or by the auto-classifier — it's redacted from the audit log, blocked from Tier 3 and any external endpoint, and can't be unflagged from the dashboard's lock-icon affordance. The only way to clear the flag is to open the trace editor and confirm the change there, two-step. Flagging is one click; unflagging is a deliberate decision. That asymmetry is the point.
The lone outbound network call is your browser fetching Three.js from cdnjs.cloudflare.com when the dashboard loads. Self-host the JS bundle if even that is too much; the recipe is in docs/data_privacy.md.
Where Synaptic fits
Synaptic is not a one-for-one replacement for Hindsight or the other extract-and-recall memory systems people are already using with their agents. It's a peer that takes a different bet on what a memory layer should do.
What Hindsight (and similar) do well
- Small banks where every memory matters and explicit curation is the right answer
- Real-time directives — operating rules an agent reads at session start
- Structured recall strategies (tag, temporal, type modes)
document_idgrouping so related facts stay reachable together- Bi-temporal queries (when did the fact occur vs. when was it written)
- Mental models — pre-computed reflect responses for high-traffic queries
- A clean reflect-vs-recall distinction baked into the API
What Synaptic adds
- Nightly consolidation pipeline grounded in neuroscience (12 phases, see below)
- Gist drift with source preservation — raw text stays immutable, the enriched version evolves
- Weighted forgetting that protects fragile-important traces (R2 SHY decay + R9 weak-trace boost)
- Cross-region recombination — surprising connections across distant regions of the bank (R6 low-similarity bridges)
- Dirty-flag re-encoding when context changes (R3)
- A live brain visualizer of the whole thing
If your workflow leans on directives or structured recall, Hindsight is the right tool. If your workflow leans on letting an agent build operational understanding of a domain over months, Synaptic is the right tool. Many people will want both — Synaptic runs alongside Hindsight cleanly, with Hindsight as the recall authority and Synaptic as the visualizer + offline consolidation layer. The two are not in a fight.
The science
Synaptic's architecture draws on 25 peer-reviewed studies on memory, sleep, and consolidation. The mapping is mechanism-by-mechanism documented in CITATIONS.md — some phases are faithful implementations (SHY weighted decay, dedup-then-synthesize, dirty-flag re-encoding under context change), others are inspired-by translations of biological processes into computational ones (replay → narrative recombination, schema reframing → drift-and-link). The system is not a paper implementation; the citations are the load-bearing structure, not a marketing badge.
If you're citing Synaptic in academic work, please also cite the underlying primary sources. The architecture is novel; the mechanisms it implements are not.
Foundations — system + synaptic consolidation
Synaptic homeostasis (SHY)
Hippocampal replay and sharp-wave ripples
Synaptic tagging and capture
Sleep-dependent transformation
Schema integration
Emotional memory and selectivity at encoding
REM-specific mechanisms (and the skeptical view)
Forgetting and pruning
REM-specific recombination + bizarre dream content
Full citations with mapping to architectural decisions →
Install
Option A — Everything in Docker
git clone https://github.com/nomadsgalaxy/Synaptic-Disorder.git
cd synaptic-disorder
docker compose up
# open http://localhost:9911Brings up the SD Core stack: a single Go binary that serves the dashboard, hosts the API + WebSocket, runs the consolidation pipeline, persists memories to SQLite. Plus per-tier Ollama containers (one per LLM model so each can be spun up on demand). No Python on host, no Node, no manual ollama pull.
Option B — Mock-only dashboard (no backend)
python serve.py
# Dashboard at http://localhost:8765Brain runs on the built-in mock event engine. Real adapter events can't reach it without SD Core; useful for evaluating the UI before committing to the full install.
Option C — Native Go binary (no Docker)
cd bridge/core
go build -o sd-core .
./sd-core --listen 127.0.0.1:9911 --data-dir ../..Single Go binary, ~15 MB static, no glibc dependency. Native Ollama for thought-bubble generation: ollama serve & ollama pull llama3.2:3b.
SD_OLLAMA_TIER1_MODEL=llama3.2:1b docker compose upqwen2.5:0.5b, tinyllama:1.1b, gemma2:2b, phi3:mini.
Remote operation
Run the dashboard on one machine, wire AI clients on others. See docs/REMOTE.md for two transport options:
- Cloudflare Tunnel + Bearer token — recommended. Two subdomains (one for dashboard, one for API),
SD_API_TOKENshared across machines, optional Cloudflare Access for SSO. - Tailscale — private mesh, no public exposure, bearer token optional.
Wire your AI client
Adapters push live events to SD Core so the dashboard reflects what your agent is doing. Each bridge ships with a config.json — edit two fields (URL + token) and you're set.
Claude Code (recommended — hooks + MCP)
Marketplace install. Hooks observe PreToolUse, PostToolUse, UserPromptSubmit, SessionStart/End, etc.; the bundled MCP server adds 17 tools (memory CRUD, research, audit/budget, dream-pipeline control).
/plugin marketplace add https://github.com/nomadsgalaxy/Synaptic-Disorder
/plugin install synaptic-claude-code@synapticClaude Desktop / Cursor / Cline / Continue / Gemini CLI — MCP
Edit bridge/mcp-adapter/config.json, then register the MCP server in your client. See AGENT_QUICKSTART.md for per-client snippets.
OpenTelemetry-instrumented apps (LangChain, LlamaIndex, AutoGen, CrewAI…)
Edit bridge/otel-adapter/config.json, start the receiver, point your OTEL_EXPORTER_OTLP_ENDPOINT at it. Works with any OpenInference instrumentation.
Anything custom — Adapter SDK
import synaptic as sd
with sd.connect(adapter_id="my-agent", model="claude-opus-4-7") as client:
client.emit("tool_call", {"tool_name": "bash"}, region_hint="motor_cortex")TypeScript SDK has the same shape. Examples in bridge/sdk/python/examples/ and bridge/sdk/typescript/examples/.